Web scraping avec Electron
9 mars 2019 · 4 min de lecture
Le “Web sraping” est une technique pour extraire le contenu des sites internet dans le but d’archiver les données de manière structurée. Attention toutefois à respecter les conditions d’utilisation du site web concerné.
Electron est un framework pour créer des applications natives Windows/Mac/Linux avec les technologies du web (Javascript, HTML, CSS). Il inclut le navigateur Chromium, entièrement configurable et manipulable.
Pouvait-on rêver mieux pour développer une application portable avec interface graphique pour scraper un site particulier ?
Le but de cet article n’est pas d’expliquer comment développer une application avec Electron. L’objectif est de décrire les techniques de scraping que permet ce framework.
Vous trouverez en bas de cette page un lien vers un dépôt GitHub avec un exemple de code source fonctionnel.
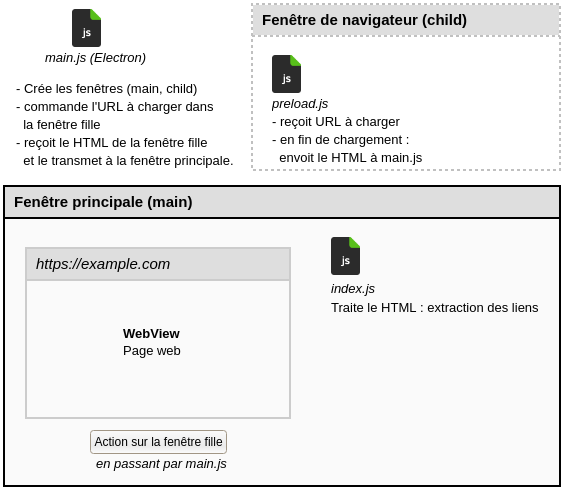
Schéma de l’application de démonstration
Navigation dans la fenêtre principale
La fenêtre principale étant destinée à l’interface de votre application, il est possible d’afficher une page web dans une webview. Cet élément permet d’intégrer du contenu dans la page courante. Pour en savoir plus, consultez la documentation Electron à propos de Webview.
<!-- Electron webview -->
<webview
style="min-height: 85vh;"
src="https://www.whatismybrowser.com/detect/what-is-my-user-agent"
useragent="My Super Browser v1.0 Youpi Tralala !">
</webview>
L’avantage est que le user-agent est configurable. Cette chaîne de texte comprend le nom de votre navigateur, sa version, le système d’exploitation et autres renseignements qui sont transmis au serveur web. Vous pouvez tester votre navigateur sur le site WhatIsMyBrowser.com.
Dans l’exemple ci-dessus les données concernant votre navigateur sont remplacées par My Super Browser v1.0 Youpi Tralala !. Cela permet de changer votre “identité logicielle” auprès du site web que vous scrapez. Il est également recommandé de changer votre adresse IP avec un VPN.
Récupération du HTML
Nous avons chargé la page https://www.whatismybrowser.com/detect/what-is-my-user-agent dans la webview, comment récupérer son contenu ? avec le code suivant qui est commenté pour explications :
// on manipule l'élément <webview>
const webview = document.querySelector('webview')
// quand la page web est chargée
webview.addEventListener('dom-ready', () => {
// on peut récupérer l'URL de la page chargée et l'afficher dans la console
let currentURL = webview.getURL()
console.log('currentURL is : ' + currentURL)
// idem pour le titre de la page
let titlePage = webview.getTitle()
console.log('titlePage is : ' + titlePage)
// on exécute du Javascript dans la webview pour récupérer le HTML
webview.executeJavaScript(`function gethtml () {
return new Promise((resolve, reject) => { resolve(document.documentElement.innerHTML); });
}
gethtml();`).then((html) => {
// on envoie le HTML à la fonction extractLinks pour traitement
extractLinks(html)
})
})
Extraction des liens
Pour naviguer dans les éléments du HTML, il existe Cheerio qui est au Javascript ce que BeautifulSoup est au Python. Voici un exemple pour extraire les liens internet contenus dans une page :
let extractLinks = function (html) {
// on charge le HTML
const $ = cheerio.load(html)
// pour chaque lien <a href=...></a>
$('a').each((i, element) => {
// on affiche l'attribut "href" et le texte du lien
console.log('href: ' + $(element).attr('href'))
console.log('text: ' + $(element).text())
})
}
Navigation dans une fenêtre fille
Electron peut ouvrir d’autres fenêtres de navigateur. Cela permet par exemple de déléguer le chargement et le traitement d’extraction dans une fenêtre cachée. Il suffit pour cela d’utiliser le paramètre show: false lors de sa création.
Exemple de création d’une fenêtre cachée dédiée au chargement des pages web :
let childWindow = new BrowserWindow({
parent: mainWindow,
center: true,
minWidth: 800,
minHeight: 600,
show: true,
webPreferences: {
nodeIntegration: false,
preload: path.join(__dirname, 'app/js/preload.js')
}
})
childWindow.webContents.on('dom-ready', function () {
console.log('childWindow DOM-READY => send back html')
childWindow.send('sendbackhtml')
})
L’option nodeIntegration: false est utilisée pour des raisons de sécurité liées à l’affichage de contenus distants. Voir la documentation Electron pour plus d’informations sur ce sujet.
Le script app/js/preload.js est injecté en amont dans la fenêtre fille. Il permettra la communication avec le programme principal en transmettant le code HTML de la page chargée.
A chaque fois qu’une page est prête dans la fenêtre fille (évènement dom-ready), le code childWindow.send('sendbackhtml') lui commande de répondre à l’évènement sendbackhtml.
Voici le code du fichier app/js/preload.js qui répond à cet évènement :
const { ipcRenderer } = require('electron')
ipcRenderer.on('sendbackhtml', (event, arg) => {
console.log('preload: received sendbackhtml')
ipcRenderer.send('hereishtml', document.documentElement.innerHTML)
})
Le code HTML est transmis au programme principal main.js qui peut le renvoyer à la fenêtre principale pour extraction des liens :
ipcMain.on('hereishtml', (event, html) => {
mainWindow.send('extracthtml', html)
})
Démonstration
Une application fonctionnelle est disponible si vous souhaitez aller plus loin et effectuer quelques tests : Sample Web Scraping With Electron. En voici une capture d’écran :
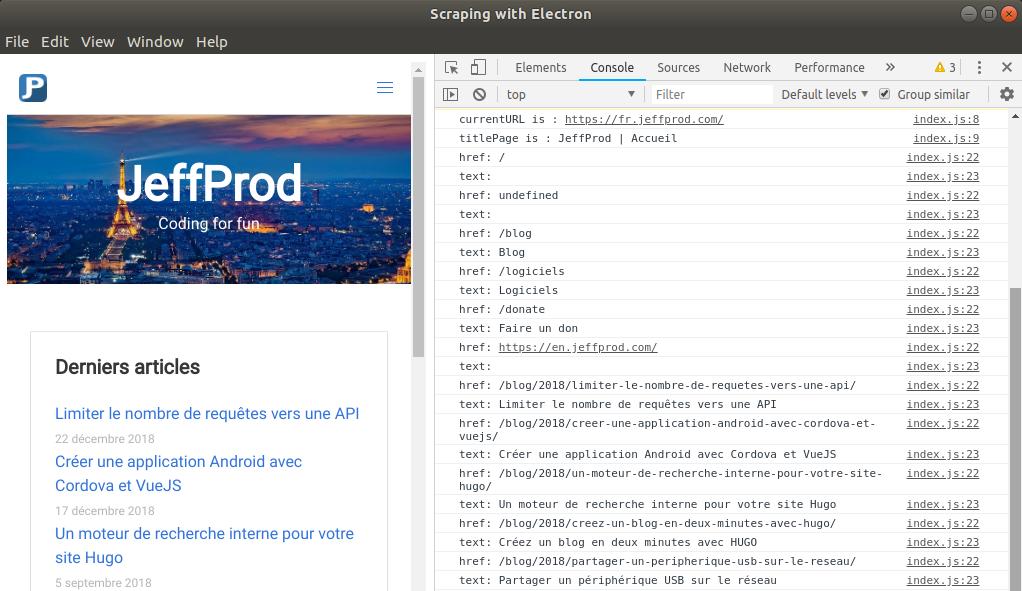 Chargement du site jeffprod.com et liste des liens contenus dans la page.
Chargement du site jeffprod.com et liste des liens contenus dans la page.
Conclusion
Vous avez maintenant toutes les billes pour développer une application de scraping avec interface graphique. La navigation peut être manuelle ou automatisée. Le chargement des pages peut être effectué dans une fenêtre fille ou dans une webview. Dans tous les cas le HTML peut être récupéré et transmis entre les composants pour traitement.
Références
- Cheerio
- Webwiew Electron
- Projet GiHtub d’exemple : Sample Web Scraping With Electron